

One of the most exciting nascent fields is that of AI agents, self learning systems that can independently reason through situations and make decisions based on new information. These AI agents are quickly becoming future employees, friends, and, in some cases, romantic companions.

In the following paragraphs, we explore a high level overview of different ways in which these AI agents, are being kept safe, and how nefarious AI agents are being stopped.
AI agents are getting good, popular, and well funded
The recent development and capital allocation to AI has been monumental. Both in terms of the absolute value of capital being deployed, as well as in regards to what this means for our future.
Intelligence, at least a decent version of it, has become a commodity. You are now able to trade OpenAI credits for tasks ranging from java script code correction to clever poetry. This is the manifestation of recent AI development that most people have seen and interacted with.
But one of the most exciting new fields in AI is that of agents.
AI agents are systems that can take actions (usually multi-step ones) they deem necessary to complete specific tasks, while reasoning through perceived changes in their environment.
The ability for code to reason through problems and changes, that haven’t been directly specified to them, is a huge unlock. Previously, the biggest issue was that you had to provide specific instructions for all eventualities. With improved reasoning abilities, there is a step change in true capabilities.
To provide some additional detail into AI agents, here is a model I put together to highlight some key concepts at each layer in an AI agent:
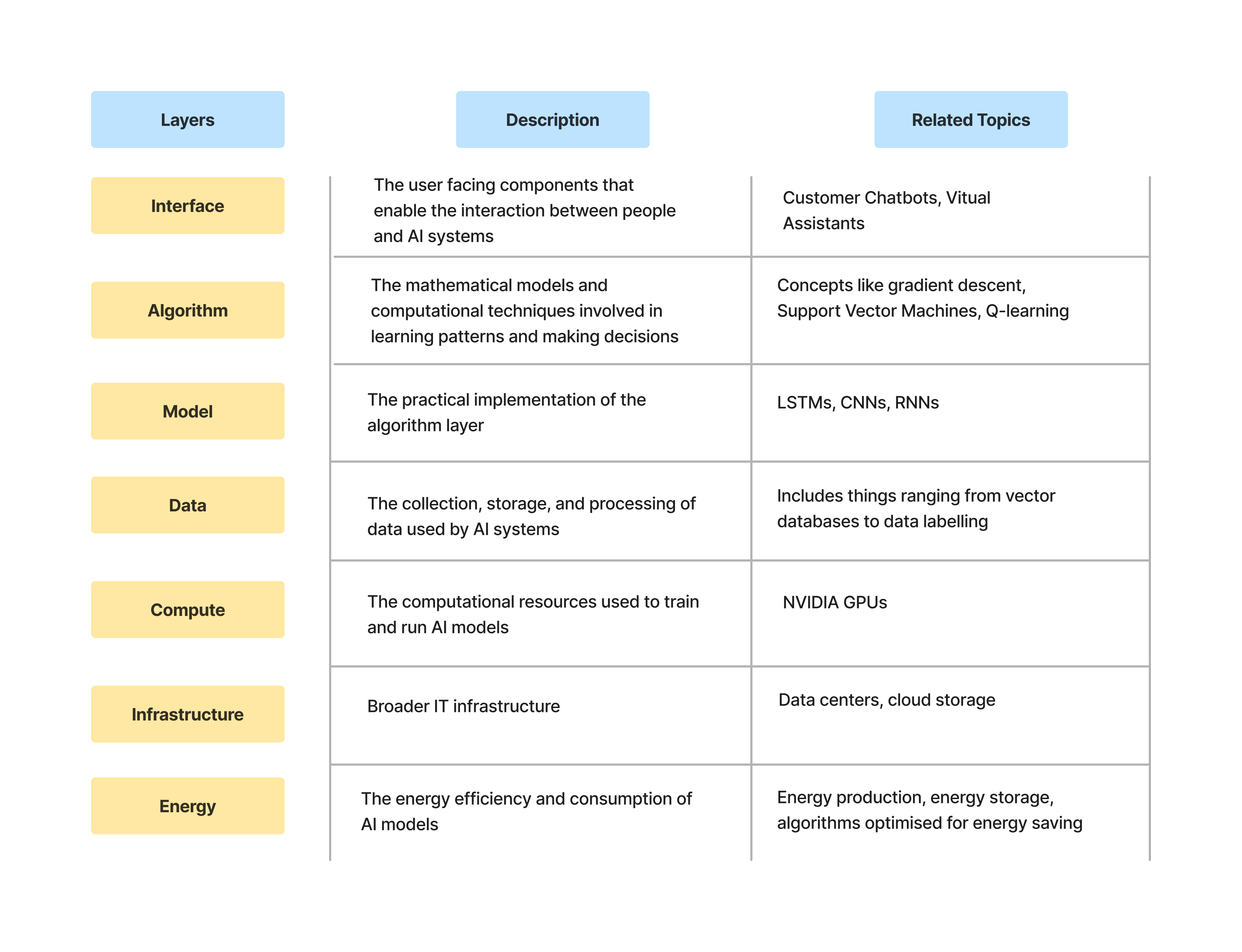
While there are a variety of different types of AI agents being built in fields ranging from Customer Support to Game Bug Testers to Personal Assistants, we won’t go too deep into them. (Insight Partners has a great AI Agent Market Map to take a look at)
What is important is the general market trend.
These AI agents are demonstrating some real value (Klarna’s customer facing AI agent answers two thirds of all questions and does the work of 700 FTEs).
Lots of these companies are being started and backed with significant venture capital. (Emergence AI raised $97M, Devin AI raised $175M, Relevance AI raised 15M)
Truth be told they aren’t perfect yet (Devin can solve about 14% of Github issues from end to end on its on). But investors are betting on their potential.
Bad actors are still bad, and getting more dangerous
While powerful tools in the right hands can lead to amazing things, the contrary is also true. We can unfortunately expect these tools to have a disastrous impact if they are taken advantage of by bad actors.
We can separate potential AI crime into two buckets (which could overlap):
Crime that is now either possible or can be done at a scale of much larger consequence.
Think AI deepfakes conducting fraud. Phishing attacks are no joke and they are about to get incredibly good and deceptive. The FBI even issued a warning on this.
Crime that can be done by leveraging or manipulating novel AI systems.
Think injecting malicious prompts into generative AI systems to get sensitive training data information
How do we protect our AI agents + ourselves?
So, if companies need to become more efficient and AI is the perfect tool at their disposal we can naturally expect rapid adoption and use (Gartner expects that 80% of companies will have used/deployed it by 2026). However, we also see the potential for harm escalating to new heights.
We need to find a way to protect our AI agents from being manipulated and we need to find a way to protect ourselves against malicious AI agents. What are the options we have?
First, lets define the agents we are looking at and breakdown the landscape.
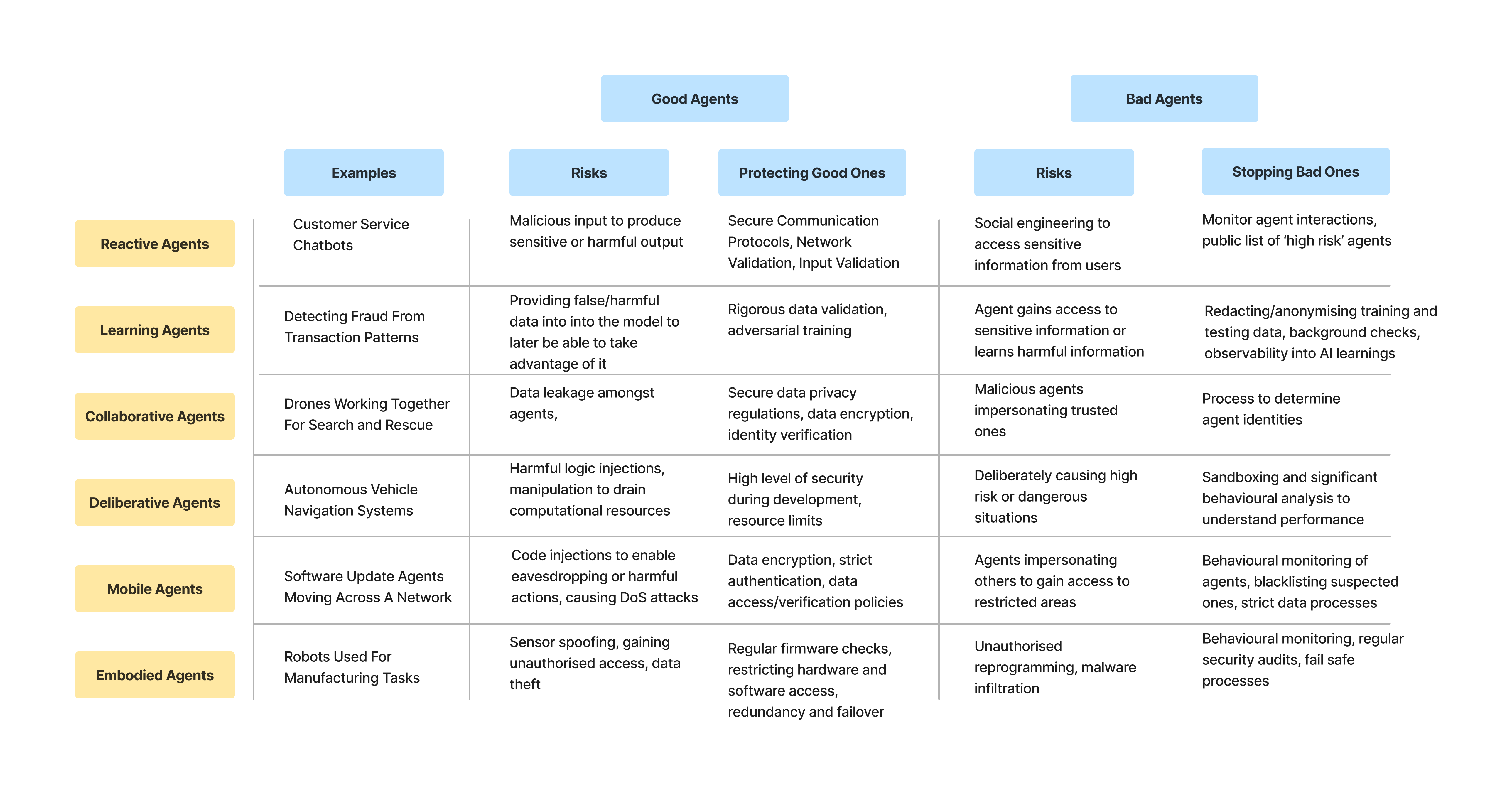
Protecting good agents
The main components involved in protecting good agents center around:
Data security, validation, and verification processes
Ensuring secure access to software and hardware
Standard cybersecurity practices such as encryption, secure communication protocols, resource limits, and redundancy
Proactive testing to detect vulnerabilities
I would argue that this is where the majority of attention and funding has been turned for now. Especially on the component having to do with data. Companies like Robust Intelligence, Calypso AI, and Lakera are example of companies focused on improving the safety of AI systems. They do it predominantly by targeting the data and proactive testing aspects mentioned above. Currently, this has been mostly for conversational AI agents but the leap to different agents isn’t an impossible one to make. This is all mostly at the Interface layer.
Quite a bit of effort has been put at Data layer as well. Incredibly well funded companies like Scale AI, are working hard to provide really high quality data for these AI systems.
Where we aren’t seeing that much novel development is in modernising legacy processes regarding secure access to hardware/software and things like encryption, resource limits, communication protocols. Given their increasing importance in AI systems, it would be interesting to explore applied and developed versions of these.
Improving the security of the Energy, Infrastructure, and Compute layers could be of high importance as well. This seems intuitive when you consider the importance of those layers. Chip maker NVIDIA became the most valuable company in the world because of how important its GPUs are to AI models. Even newer competitors in the space, like Etched, have raised $120M to compete.
Stopping bad agents
While we have seen lots of work done in protecting good agents, there is much to be done when it comes to stopping future bad agents.
The main topics we touched on in our landscape regarding ways to stop bad agents include:
Monitoring agent interactions + behaviour analysis
Background checks on agents and developers
Process to verify agent identities before providing info and access rights
Blacklisting agents that are shown to be dangerous, reckless, toxic or otherwise harmful
Clear observability into AI agent learnings
Effective sandboxing environment for testing
We can synthesise these into a few manifestations that are really interesting.
AI God Agent
This is the idea of a single AI agent in charge of monitoring all agents in a system. It tracks their behaviour and monitors for anything malicious or not functioning well. It then has the ability to provide a clear summary with insight and recommendations for people to read and act on. The flip side would be the risks associated with concentrating power in one single AI agent - it better be secure.
Formal Security Guarantees
This is a way to enforce hard constraints on AI systems. Think of it as hard blocks on certain actions, or sequences of actions, that AI agents may take. It works to get rid of potential ambiguity on if something is acceptable or not. This could work great when dealing with short sequences, and straightforward agent actions, but becomes exponentially more challenging as sequence length and complexity spirals.
Potential solutions to dealing with the complexity in determining what is ok or not include using humans or LLMs to judge more complicated cases. LLMs can be improved over time at this by using humans to give feedback on their decisions for more nuanced cases. A form of RLHF.
Not only does this prevent malicious behaviour but it also acts to prevent accidental malfunctions from good agents.
Public Ledger
This is the idea of a public trusted source of information which collates insight on various AI agents (as well as the developers of them). It contains benchmarks, detailed contributions from users, and recommendations regarding safety. Potentially enabled through a decentralised platform.
KYA (Know Your Agent)
This has to do with a secure way of verifying agents. When agents begin to collaborate with one another and move around networks. This will be incredibly important to ensure access and information is provided securely.
Sandbox Red Testing Platforms
This is the idea of a place where individuals/businesses can upload agents to isolated environments and have them pressure tested by a series of ‘red-teaming’ agents (agents purposefully trying to find vulnerabilities). Some variations of AI agents which do this type of testing currently exist but I foresee this becoming far more versatile and specific for tailored circumstances.
If I am going to implement a medical chatbot in my hospital for diabetic patients to help track the food they consume, I care about very different things than if I were going to create an excel analysing agent for hedge funds. Yes, there are some fundamental similarities in what they likely care about, such as basic data security, but also some very disparate ones. Such as the redaction of PII data.
I could also imagine this as a market place, where you can ‘rent’ red teaming agents of varying costs and ability to test chosen agents. The more sensitive the context in which you are going to use an agent likely the more money you’d be willing to spend on thorough testing. These concepts also don’t exist in isolation, I could see sandbox red testing platforms releasing certifications of safety, which public ledgers would take into consideration.
This an incredibly interesting and quickly developing field, with tremendous importance. I will definitely return to do a deeper more technical dive into the space.
If you’re building something in the space or are even just exploring it, reach out to me. I’d love to brainstorm, trade ideas, or even just learn what you are doing.